Linux
Come Leggere un File Riga per Riga in Bash
Apple17 ore ago
Come eseguire nuovamente le app per iPad a schermo intero in iPadOS 26
Apple3 giorni ago
Come cambiare il colore dell’icona della cartella su MacOS Tahoe
Apple6 giorni ago
iPhone disconnesso dall’acquisizione di immagini durante l’importazione? Prova questa soluzione
Apple1 settimana ago
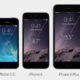
Utilizzi un iPhone 5s, iPhone 6 o iPhone 6 Plus? Ottieni l’aggiornamento iOS 12.5.8 per mantenere iMessage e FaceTime funzionanti

Apple1 settimana ago
Stirling-PDF: l’alternativa gratuita ad Adobe Acrobat per lavorare con i PDF
Apple1 settimana ago
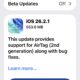
Aggiornamento iOS 26.2.1 rilasciato per iPhone e iPad con correzioni di bug e supporto AirTag 2

Apple3 settimane ago
Il mouse o le tastiere Logitech si rompono sul Mac dopo la scadenza del certificato, ma è una soluzione semplice
Apple4 settimane ago
PowerFox porta un browser Web moderno sui Mac più vecchi con Snow Leopard
Apple4 settimane ago
Come aggiornare a iPadOS 26 su iPad

Apple2 settimane ago
btop per MacOS è un eccellente monitor delle risorse del sistema terminale
-

 Apple5 anni ago
Apple5 anni agoNon riesci a scaricare app su iPhone o iPad? Ecco come risolverlo
-

 Apple5 anni ago
Apple5 anni agoCome disattivare la suoneria per un singolo contatto su iPhone con un trucco suoneria silenzioso
-

 Apple5 anni ago
Apple5 anni agoIl microfono dell’iPhone non funziona? Ecco come risolvere e risolvere i problemi del microfono di iPhone
-
 Apple5 anni ago
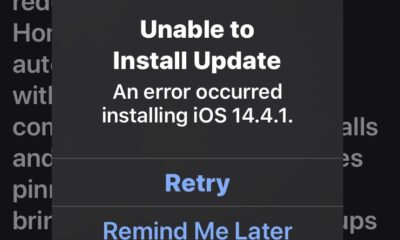
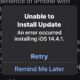
Apple5 anni agoCorreggi l’errore “Impossibile installare l’aggiornamento” per iOS e iPadOS