Connect with us


Se stai andando a guardare i fuochi d’artificio questo 4 luglio, potresti voler catturare i momenti con alcune fantastiche foto o video di fuochi d’artificio. Con...


La creazione di un programma di installazione MacOS Tahoe Avviabile è un modo utile per eseguire installazioni pulite, aggiornare più Mac senza scarico ridotto o mantenere...
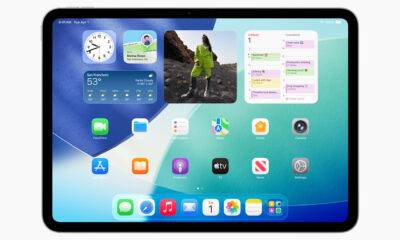

Ipados 26 offre un set avvincente di funzionalità per gli utenti di iPad che hanno richiesto da tempo, tra cui finestre simili a Mac, funzionalità multitasking...
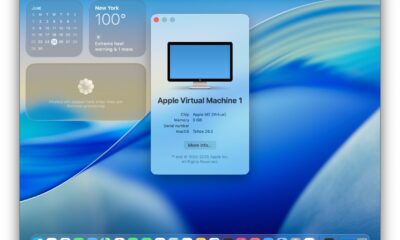

Gli utenti Mac avanzati che sono esperti con la riga di comando possono costruire una macchina virtuale beta MacOS Tahoe 26 emettendo alcuni comandi nel terminale,...

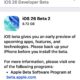
Apple ha rilasciato iOS 26 Beta 2 per iPhone, insieme a iPados 26 Beta 2 per iPad, per gli utenti che partecipano ai programmi di beta...

Se hai tentato di installare MacOS Tahoe Beta in una macchina virtuale utilizzando il programma di installazione Tahoe o IPSW, potresti eseguire un errore di loop...


Se hai recentemente acquisito alcuni nuovi AirPod o AirPods Pro, potresti trovarti in una situazione in cui ti stai chiedendo se gli ultimi modelli di AirPod...
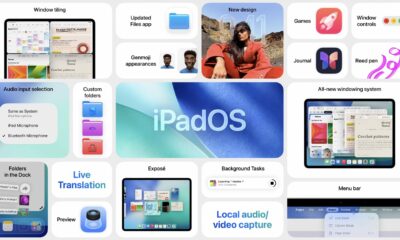

Ipados 26 è stato annunciato e offre alcune delle modifiche più significative a iPados da un po ‘di tempo. Con un’enorme enfasi sul miglioramento delle funzionalità...


IOS 26 è uscito, con la sua nuova interfaccia di vetro liquido lucido e nuove funzionalità come background e polling nell’app di messaggi, miglioramenti a Apple...


MacOS Tahoe 26 è qui, e fin dall’inizio puoi vedere la differenza con l’aspetto e lo styling di interfaccia di vetro liquido, con il suo uso...
Quando visiti un sito Web, esso può archiviare o recuperare informazioni sul tuo browser, principalmente sotto forma di cookies. Controlla qui i tuoi servizi di cookie personali.